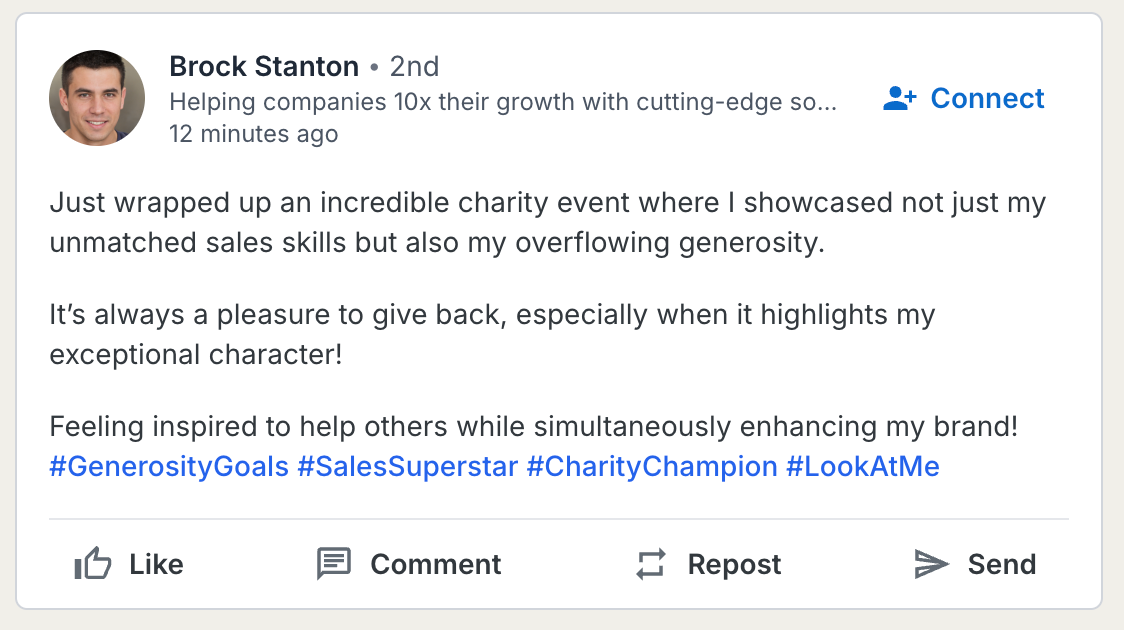
View Demo: Sales Bro
Background
It's really dumb. I know, but hey it's fun.
Imagine a world where LinkedIn was just ones unbearable sales bro posting inane shit all the time.
Imagine no more!
Tech/tools used
- Cloudflare Pages
- Cloudflare Page Functions
- Cloudflare KV
- OpenAI
- Langchain.js
- Langsmith
The build (webapp bits)
Continuing to build on Cloudfront Pages & Page functions, this was a fairly simple exercise to have a React component poll an endpoint to fetch posts from the backend.
Backgrounding the post generation
I wanted to avoid having a "generate new post" button, lest it gets spammed by someone etc. In an ideal world, I wanted
it so that when you loaded the page, it generated a new post. It can take a little bit of time to generate a post (see
The LLM stuff section), so I didn't want to have the user wait for a new post being generated before they could see
any posts.
I'd generally reach here for a background worker that runs off a task queue, but Cloudflare worker queues are only available on the paid plans and it's not really worth it for this.
Instead, I pieced together a bit of a hack. When the user first loads the page, the frontend hits the route naked, we load the "old" posts from a KV store (lazy man's database) but we background the work of generating a new post, but still within the same worker execution. This way, the user gets a response quickly, but we're still generating a new post in the background, even if it takes a little bit of time.
It's definitely not as robust as a proper task queue, but it's a fun little hack!
// Simplified example of the request handler
export const onRequest: PagesFunction<Env> = async (context) => {
const oldPosts = await postStore.getPosts();
// context.waitUntil tells the worker that work is still happening, but it's async so we're not blocking the response
context.waitUntil(async () => {
const post = await generatePost(context.env.OPENAI_API_KEY)
postStore.addPost(post)
});
return Response.json({
posts: oldPosts,
});
};Using tanstack-query for polling
To setup the polling of the frontend to the backend, I used tanstack-query (FKA react-query). This was the first I'd come across this library before but boy it's pretty neat!
It was simple enough to implement some behaviour where the frontend kept track of a timestamp of the latest posts
created_at, then on subsequent requests it sends through ?since={timestamp} to the backend. The backend then checks
if there's been any new posts since that timestamp. If there's been no new posts since then it returns
a 204 - No Content, otherwise it returns all the posts. (It should probably just return the "new posts" but it's not
particularly consquential for this).
There was a bit of "holding it right" to get tanstack-query to play nicely with the 204 response. The code below shows
the work around - capturing the 204 as a custom error, then overriding the retry behaviour.
// Truncated example of using tanstack-query to handle 204 response and sending since params
const expectedResponse = z.object({
posts: z.array(postSchema),
});
export class NotModifiedError extends Error {
constructor() {
super('Response not modified');
}
}
export const loadPosts = async (since: null | string): Promise<Post[]> => {
const url = new URL('/salesbro/posts', window.location.origin);
if (since !== null) {
url.searchParams.set('since', since);
}
const response = await fetch(url);
if (response.status === 204) {
throw new NotModifiedError();
}
const {posts} = expectedResponse.parse(await response.json());
return posts;
}
const loadPostsAndSetSince = async (data: undefined | QueryState): Promise<QueryState> => {
const posts = await loadPosts(data?.since ?? null);
const since = posts.length > 0 ? posts[0].created_at : null;
return {
posts,
since
};
};
const query = useQuery({
queryKey: ['posts'],
queryFn: (): Promise<QueryState> => loadPostsAndSetSince(query.data),
retry: (_, error) => {
if (error instanceof NotModifiedError) {
// Don't retry - it's fine bro
return false;
}
return true;
},
refetchInterval: 5000
});The LLM stuff
Continuing on from my talk on Langchain and having worked with it a fair bit now at work, I picked up my trusty tools again.
This problem was different for me though! All my other usages have been in use cases where accuracy/precision is prioritised, but here the goal was creativity. How can you meaningfully evaluate something when what you're looking for is inherently beautiful hallucinations?
I first tried getting the model to generate the post directly in a single LLM call. This took a fair bit of prompt engineering to get remotely good and I found that even when I dialled the temperature up, it was still pretty boring and easily got stuck on a few topics.
I then branched out to try and break down the problem into more discrete steps:
- Generate an outline for a post
Example prompt below. {postIdea} would be a random selection from a list of broad themes.
You are tasked with drafting an outline of a LinkedIn post for a narcissistic enterprise software salesperson for
satirical, entertaining purposes.
General post idea: {postIdea}
Generate the outline of the post.
The outline should be {bulletCount} bullet points in length.
Each bullet point should be less than 10 words.
The outline should be specific and detailed.Example output:
{
outline: "1. Big announcement: I'm leaving LinkedIn. \n" +
"2. But wait, there's more! \n" +
"3. Can't resist sharing my brilliance! \n" +
'4. Expect more posts than ever before!'
}- Use the outline to generate the post
Example prompt below.
You are tasked with drafting a LinkedIn post for a narcissistic enterprise software salesperson for satirical,
entertaining purposes.
Post guidelines:
- the post should follow the outline provided
- the post should be cringe-worthy
- the content of the post should be 10-50 words long
- each paragraph should be one sentence long
- separate paragraphs with one newline character
- include 0-10 hashtags that are relevant to the post, but also cringeyResults
Again, I'm not really sure how to evaluate anything here beyond vibe checks.
The results are OK, but they do get pretty monotonous even when dialing up the temperature. For example, it seemingly always talks about the coffee shops when prompted around "local business" themes, but there's no direct reference to coffee shops. It surprises me how focussed it is on coffee shops with a high temperature!
I think getting the model to generate more specific details (with temperature still high) would be a good progression but it's really just a toy project and the creativity direction of using LLMs is not really something I've explored much or have a great interest in.
What I could do next
Things I'd love to do to build upon this:
- Store the posts in a D1 db - it's better suited for the task, I just couldn't be bothered creating a table schema haha
- Continuously randomly generate users, taglines and profile pictures
- "this person does not exist" generates some pretty good profile pictures, so it's pretty achieveable.
- I'd need to store the profile pictures on R2 which is the Cloudfront equivalent of S3 so that'd be good to learn!
- It'd be fun to allow public users to like posts too, that'd make a good live demo!